OpenMS is a flexible codebase that can be tailored to many different applications ranging from the standard label free analysis to top down, metabolomics, crosslinking or DIA.
OpenMS is used in a variety of applications: popular third-party apps which run OpenMS under the hood include
Applications which are integrated into OpenMS releases or are available as pipelines (e.g. using KNIME or Nextflow) are listed below. The pages will provide explanations on how OpenMS can be used to solve your problems and link to workflows that allow you to apply the tools to your data.
If you cannot find your application in the menu on the left, more OpenMS tools can be found in the TOPP documentation.
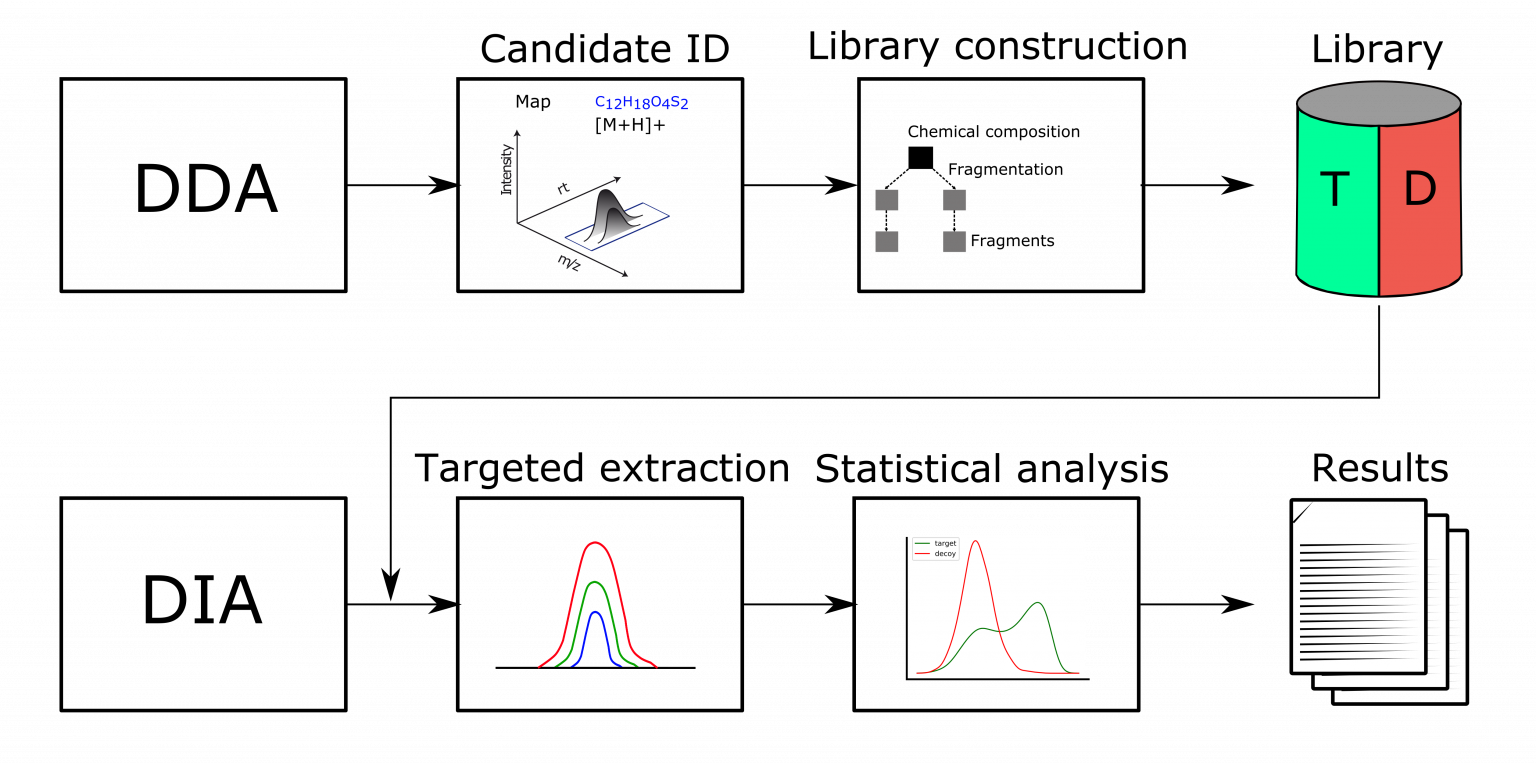
DIAMetAlyzer is a KNIME workflow which integrates DDA and targeted DIA analysis for metabolomics, which allows for false-discovery rate estimation based a target-decoy approach (see figure 1). It performs DDA based candidate identification and constructs a target/decoy assay library, which is used for DIA target extraction and statistical validation (FDR estimation)
Fig. 1: DIAMetAlyzer – pipeline for assay library generation and targeted analysis with statistical validation
DIAproteomics is a bioinformatics analysis pipeline used for quantitative processing of data independent (DIA) proteomics data.
The workflow is based on the OpenSwathWorkflow for SWATH-MS proteomic data. DIA RAW files (mzML) serve as inputs and library search is performed based on a given input spectral library. If specified internal retention time standards (irts) will be used to align library and DIA measurements into the same retention time space. FDR rescoring is applied using Pyprophet based on a competitive target-decoy approach on peakgroup or global peptide and protein level. Optionally EasyPQP can be used for library generation and DIAlignR for chromatogram alignment and quantification.
EPIFANY is a tool for efficient bayesian protein inference. It is included in OpenMS since 2.5.
It takes one or more peptide database search engine results (in OpenMS’ idXML format) that were post-processed
by the PercolatorAdapter or IDPosteriorErrorProbability tool and adds posterior probabilities and/or
false discovery rates for each protein or protein group to it.
Ultra-fast MS1/MS2 deconvolution for top-down proteomics
FLASHDECONV 2.0 BETA+, FINALLY WITH A GUI!
Finally a GUI is here. You can find the GUI command in [OpenMS path]/bin folder. Go to [OpenMS path]/bin and run FLASHDeconvWizard! FLASHDeconv 2.0 beta+ works for MS1 and MS2 spectral deconvolution and feature deconvolution. It supports various output formats (e.g., *.tsv, *.mzML, *.msalign, and *.feature). FLASHDeconv 2.0 stable version will be officially integrated in OpenMS 2.7.0 released in near future. FLASHDeconv 2.0 beta+ also supports TopPIC identification better than the previous version, by generating all msalign and feature files for TopPIC inputs. We also added spectral merging function to support QTOF dataset analysis and NativeMS dataset analysis.
Intelligent data acquisition for top-down proteomics
FLASHIda
FLASHIda is an intelligent online data acquisition algorithm for top-down proteomics (TDP) that ensures the real-time selection of high-quality precursors of diverse proteoforms. FLASHIda combines fast decharging algorithms in FLASHDeconv and machine learning-based quality assessment to identify optimal precursors for fragmentation. Currently the C# source code and instruction of FLASHIda is available in here under a BSD three-clause license. We are working on merging FLASHIda into OpenMS.
Output: Quantified proteoforms in a tab-separated file (*.tsv); optionally, OpenMS LC-MS features output (*.featureXML)
for each proteoform, mono-isotopic/average mass, retention time range, charge range, different types for quantity values, and isotope cosine similarity score are provided.
Parameters can be found by running FLASHQuant using the “–helphelp” option.
FLASHQuant executes per LC-MS run; thus, we provide an additional simple tool for detecting consensus feature groups (i.e., jointly detected proteoforms) among multiple scans (i.e., technical replicates) named ConsensusFeatureGroupDetector. Retention time and mass tolerance can be adjusted with parameters.
Quantification and identification workflow for MHC peptides
MHCquant: Identify and quantify peptides from mass spectrometry raw data
MHCquant is an nf-core best-practice bioinformatics analysis pipeline used for quantitative processing of data dependent (DDA) peptidomics data.
It was specifically designed to analyze immunopeptidomics data, which deals with the analysis of affinity-purified, unspecifically cleaved peptides presented on major histocompatibility complex (MHC) molecules.
This analysis has central implications for clinical research and T cell-centric immunotherapies in the context of cancer vaccines and personalized medicine.
NASE is now included in OpenMS release, 2.5 or later.
Requirements:
HCD (or ETD) data of RNA oligonucleotides acquired on a high-resolution mass spectrometer
Fragment spectra (MS/MS) need to be centroided (either on acquisition, conversion, or in a workflow using the TOPP tool PeakPickerHiRes)
Developed and tested on Linux (Ubuntu 18.04 and 18.10) systems with data from orbitrap instruments
Operating system: OpenMS installers have been tested on Ubuntu Linux 18.04, Windows 7/8/10, and macOS 10.12-10.14. If you experience any troubles don’t hesitate to contact the OpenMS team or open an issue in the OpenMS GitHub repository.
Publication:
Wein, S., Andrews, B., Sachsenberg, T. et al. A computational platform for high-throughput analysis of RNA sequences and modifications by mass spectrometry. Nat Commun 11, 926 (2020). https://doi.org/10.1038/s41467-020-14665-7
NuXL is a novel tool for protein-RNA and DNA cross-linking studies. It is available as a
stand-alone tool and as a Proteome Discoverer community node or as a web application that doesn’t require you to install additional software. This guide outlines the steps to install NuXL, set up your analysis, and interpret your data using the provided tools and workflows.
Requirements:
HCD data acquired on a high-resolution MS
Developed and tested on orbitrap instruments (including Velos, Lumos, and Astral)
Installation for Proteome Discoverer
NuXL is currently compatible with Proteome Discoverer 3.0 and 3.1.
OpenPepXL: an open source peptide cross-link identification tool
OpenPepXL is a protein-protein cross-link identification tool implemented in C++ as part of OpenMS. It works with all uncleavable labeled and label-free cross-linkers but not (yet) with cleavable ones.
Requirements
The current version of OpenPepXL, version 1.1 is available as part of OpenMS 2.5. Installers for Windows, MacOS and Linux can be found here. OpenPepXL can be used effectively on a desktop computer with 16BG of memory.